



StrongARM Versus the World
Stephen Streater of Eidos explains what's special about the StrongARM design, and compares the chip to its predecessors and rivals.
As part of our series looking back at the past 20 years of RISC OS we are returning the launch of the StrongARM processor and are comparing it with its rivals.
The release of the StrongARM is the latest major step in the progress of the ARM design and implementation. The chip comes on an Acorn processor card similar to the ARM610 and ARM710 cards. Although it can be plugged in at the same time as a PC card, it cannot be used at the same time as previous versions of the ARM processor card for RiscPCs.
Some of the differences between the new and old processor cards are outlined below.
As clock rates have increased, so have radio emissions from circuits. To combat this problem, the StrongARM supports a slow and commonly available input clock crystal of 3.68MHz, which is then multiplied up inside the chip. The multiplier factor is determined by four pins on the chip, and can be altered by setting DIP switches on the StrongARM card.
The cards themselves had the DIP switches bypassed to give a clock speed of 55 x 3.68MHz (202.4MHz). Although it was quire possible to overclock the chips by as much as 50% to get them up to almost 300Mhz. This has been covered in a previous Foundation RISCWorld.
The ARM610 and ARM710 can be supplied with a 5V input level, but the StrongARM would burn out at these voltages, and so the voltages supplied to the chip are reduced to 3.3V and 2.4V. The StrongARM upgrade card is very similar in size and appearance to the ARM610 and ARM710 card. So unlike a Pentium processor there is no massive heatsink!
From ARM to StrongARM
Most ARMs run at various clock rates depending on whether they are waiting for external memory chips (e.g. in SIMMs or VRAM) or external hardware devices. The clock rate in Table 1 (below) is the speed at which each type of ARM runs when it is not held up by waiting for external devices. In earlier ARMs this corresponds to the memory speed of the computer they were in, and in later ARMs to the speed at which they can access their internal cache memory.

Table 1 : Clock speeds
As processor chips got a lot faster, memory chips got a lot bigger and only slightly faster.
By the time the ARM2 came along, it was entirely constrained by memory. To combat this developing problem, modern processors include a small amount of on-chip memory, called cache. Almost all of the transistors in a modern CPU are in the cache. Too much cache (and hence too many transistors) reduces the percentage of working chips coming off the production line, driving up the cost of the chips. As manufacturing techniques have improved, cache sizes have increased. The cache sizes in table 1 are measured in kilobytes.
With standard cached ARMs (ARM3, ARM610 and ARM710), data can be read very quickly from the cache, but writing data is slow because the ARM waits for it to arrive at its relatively slow destination before continuing. This cache design is called write-through, and was chosen because it is cheap to make and old software is compatible. The StrongARM, however, marks a major departure in cache design. The previous single cache for instructions and data is replaced by two caches: the instruction cache (I-cache) and the data cache (D-cache).
The I-cache is intended to contain just instructions, and is only updated directly from memory when instructions are read in. This means that writing to memory to update a program will not affect the contents of the I-cache, making the StrongARM incompatible with previous ARMs in the case of self-modifying code. Programs such as those produced on the Acorn C/C++ compiler are not affected, but a lot of copy-protection systems had to be rewritten to work with a StrongARM.
The D-cache is a write-back cache: writes to memory in the cache are not written to external memory until the cache line they are in is needed for something else, and then only if that part of the cache has been written to. This reduces the amount of memory traffic enormously, because most workspace used by a program will never go off chip, and so will not be constrained by the internal memory of the computer. The effectiveness of this design caught even Acorn themselves by surprise.
You might think that in an ideal world, every byte of memory would be cached independently, but it turns out that the bureaucracy needed to keep tabs on where every byte came from in memory is excessive. Instead, information is cached in chunks called cache lines. Having lots of cache lines is generally good, as it means that information from lots of different places in memory can be cached at the same time.
ARM cache lines consist of four or eight 32-bit words, allowing efficient access to the external memory chips which can access sequential memory quickly.
Each memory location can only be stored in a subset of the cache. The number of places each cache line can go into is the set associativity of the cache. In the ARM3, the set associativity is 64. This is much higher than typical chips (the original Pentium dsign has only had two choices) and makes the cache very efficient.
The ARM710 set associativity was reduced to save power. In the StrongARM, which depends on high cache hit-rates for its speed, it was increased again.
The write buffer allows writes which do go out to memory to be stored on the chip while the processor carries on at full speed on the next operations. Table 1 quotes two numbers for each relevant chip: the first is the minimum number of writes which could fill up the write buffer.
The second is the maximum number of writes needed to fill up the write buffer. Each write can be one byte or four bytes. The StrongARM write-back D-cache always uses its write buffer optimally (i.e. it will always use all 128 bytes in the write buffer if the only memory writes are caused by D-cache write-backs).
The StrongARM has other advantages over previous chips: instructions which took more than one cycle on previous ARMs take fewer cycles. For example, a branch instructions takes two instead of three cycles, and cached memory accesses are between two and three times faster than before.
Finally, the multiply instruction has been enhanced significantly, making it up to 40 times faster than on the 30MHz ARM610.
A number of StrongARM features are not implemented on the Risc PC. These mostly concern tweaks to the performance of the write buffer, and include 16-bit reads and writes to external memory.
Dhrystone benchmarks
To put the StrongARM's performance in perspective alongside its mainstream rivals in desktop computers at the time, I have performed some Dhrystone benchmark timings on a variety of Risc PCs, Wintel PCs and PowerMacs. The Dhrystone benchmark, carefully chosen to represent typical integer instructions as used in typical programs, has been compiled twice on several machines to produce table 2. The slow time (smaller number) corresponds to the default compiler settings, with the fast time corresponding to the maximum optimisation setting. The PowerMac (PowerPC chip) versions were compiled without optimisation, as required to give valid readings according to the Dhrystone instructions (the two values represent the two compilers we use on the Mac). The Acorn versions are further subdivided to show the speed when single-tasking outside the desktop and when multitasking from a task window.
Finally, all working OS/chip versions for Risc PC are compared to show differences in OS performance. The Wimpslot was set to 16Mb in the task window cases.
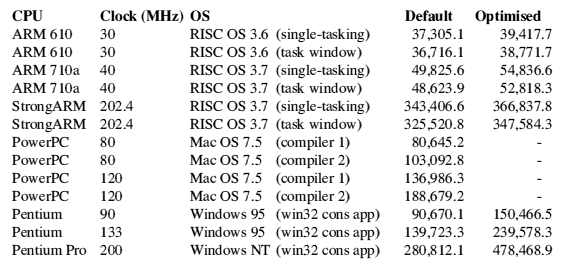
Table 2 : Dhrystone benchmarks
The Acorns used the Acorn C release 5.06, and the PCs used the Microsoft Visual C++ 4.1 compiler. There are rumours that Microsoft has geared its optimisations around the Dhrystone benchmark program, but who am I to comment? The figures all vary slightly between runs. The OS version didn't seem to affect the benchmark rating significantly on the ARM610 and 710.
You may be wondering why the Pentium Pro came out so fast. Well, if you read the Dhrystone instructions it tells you not to enable optimisation, because it is a processor benchmark and not a C-compiler benchmark. Under these circumstances, the StrongARM comes out as the fastest processor. So what naughty optimisations were implemented on the PC compiler? Things like in-line function expansion for small functions (effectively converting them into macros and removing any stack overheads in function calls) and writing out loops more often are fairly safe. Removing repeated allocations within loops, together with local and global common sub-expression elimination, could remove the entire Dhrystone program if taken to their logical conclusion! There are also optimisations which can break programs in certain cases, such as removing stack checking on function calls and assuming that no function affects data in its calling routine.
Chess benchmark
Benchmarks have often been cricised for being unrepresentative, so I thought I'd add my own. Originally written for an ARM2 in 1988, I have been improving my chess program on and off since then. It is written in ARM machine code, and I have been gradually increasing its efficiency over the years. The program does an exhaustive search up to the ply stated, then a quiescent search over only 'significant' possibilities until the position stabilises.
(Ply tells you how many moves the program has looked ahead: one ply is one move for one player, and so seven ply is four computer moves and three opponent moves.).
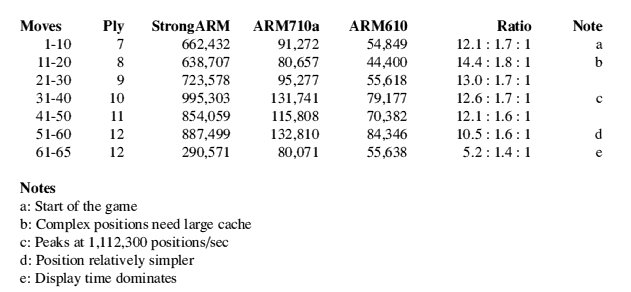
Table 3 : Chess
I have played through the same game on a StrongARM, 710a and 610 and averaged the moves/sec figures for each batch of ten moves, and printed this average figure as well as the ratio of the speeds of the various chips. The results appear in table 3 (above). It is interesting to note that the StrongARM peaks at around a million moves/second, and performs up to fourteen times faster than the ARM610.
Needless to say, the ARM610 was much faster than the ARM3 it replaced, which was in turn much faster than the 8MHz ARM2 (which managed around 5,000 moves per second on the then-current version of the program).
It is interesting to remember that the original dedicated Deep Thought chess computer made by IBM managed around 1,000,000 positions per second, so the StrongARM is not far behind (although the Deep Thought computer did have a much better understanding of the positions it looked at).
Conclusion
Although the memory runs at the same speed as before, the StrongARM's on-chip cache and write buffer are so large and well designed that the chip is able to run at its full speed for most of the time. The StrongARM was a bigger step up in performance than the ARM2 to ARM3 upgrade.
If you don't already have a StrongARM upgrade for your Risc PC, and there can't be many that don't then get one! APDL always have various versions ins tock up to the 287 Mhz Turbo version.
Design Objectives
As a final note it's worth comparing the various objectives of the chips that were available when the StrongARM launched in 1996:
PowerPC:
a chip designed by committee (including IBM and Apple, previously less friendly than Bill and Larry!). This chip is very fast, and includes several instruction sets so that Apple and IBM programmers can all feel happy. Nice features include: 32 registers, lots of condition flags, and a fast inbuilt floating point unit.
Pentium Pro:
designed to improve on the Pentium, while still retaining compatibility with 8-bit processors from pre-history. This includes the Level 1 cache and a mammoth Level 2 cache on the chip. It also does speculative execution, where instructions are executed in advance in case the results are needed later, and it supports multiple execution units.
Alpha:
designed to be the fastest chip in the world; power consumption and cost no object. Simple instructions with multiple instruction issue and very high clock rates ensure high speed.
StrongARM:
designed to be fast and cheap, and ideal for embedded systems or low-cost computers; the only supercomputer to run off batteries. It uses the Alpha production technology and the ARM instruction set, with the result that it has a price and power consumption like an ARM, but performance like an Alpha. However it excluded a 64-bit external bus, floating point, on-chip Level 2 cache, and multiple instruction issue per cycle.
Stephen Streater